C/C++ Includes as graphs
Intro
At some point of time you want to see the dependencies inside of your project.
This can be useful for optimization of compilation times, and also from design perspective.
One of the nice representation is graph where vertexes is files and edges is include statements.
This representation is very powerful for analysis because it gives us the whole graph theory tricks to use.
I have used it to find which files it is better and safe to include into precompilation header, and also to gain some nice overview of the project.
Technologies used
I have ended with python + orientdb + gephi.
My first try for our relatively big project was python + graphviz.
I have failed with graphviz because it was trying to produce a png for 4 hours(4k vertexes + 30k edges).
The second attempt was with graph database.
I have decided that for analysis purposes it is a way better to load everything in database which allows you to do custom queries.
So I took orientdb - installation very straightforward and the documentation is nice.
I will use visualization of CPython project here.
Short OrientDB intro
OrientDB allows you to do SQL like queries over its database and also have a beautiful one web client interface.
screenshot of orientdb web interface
{kind=link}
It is document oriented db with possibility to store graphs. It can be schema-less, or you can create a scheme and use it.
Classes is almost like tables in regular one SQL(actually it is not so, but for simplicity reasons lets assume it is so).
It also have a nice one python bindings.
Putting it all together
Source code
You can obtain source code from bitbucket
https://bitbucket.org/dehun/cpp_dependencies/src
Or you can read it below
import re
import os
import fileinput
import multiprocessing
import pyorient
def get_file_list():
return [f.strip() for f in fileinput.input()]
def disambiguate_filename(path):
return os.path.basename(path)
def disambiguate_dependency(dep):
return (disambiguate_filename(dep[0]),
disambiguate_filename(dep[1]))
def disambiguate_dependencies(deps):
return [disambiguate_dependency(dep) for dep in deps]
def read_dependencies_from_file(filepath):
print '[i] reading dependencies from file ' + filepath
with open(filepath) as fin:
return [(filepath, dep) for dep in
re.findall(r'#include ["](.+?(?:h|hpp))["]', fin.read())]
def read_dependencies_from_files(file_list):
# read raw dependencies
dependencies = []
pool = multiprocessing.Pool(100)
results = pool.map(read_dependencies_from_file, file_list)
dependencies = [item for sublist in results for item in sublist]
# disambiguate
dependencies = disambiguate_dependencies(dependencies)
# count em
counted_deps = set()
for left_dep in dependencies:
count = len([d for d in dependencies if d == left_dep])
counted_deps.add((left_dep[0], left_dep[1], count))
print 'got %s dependencies' % (len(counted_deps))
return counted_deps
def save_graph(deps):
print 'saving graph'
vertices = set()
for d in deps:
vertices.add(d[0])
vertices.add(d[1])
edges = deps
orient = pyorient.OrientDB()
orient.connect("root", "system")
# orient.db_delete("cppdepdb")
orient.db_create("cppdepdb", pyorient.DB_TYPE_GRAPH)
orient.db_open("cppdepdb", "root", "system")
orient.command("create class cppfile extends V")
orient.command("create class cppinclude extends E")
for v in vertices:
orient.command("create vertex cppfile set name='%s'" % v)
for edge in edges:
orient.command("create edge cppinclude from"\
"(select from cppfile where name='%s') to"\
"(select from cppfile where name='%s') set count='%s'"
% (edge[0], edge[1], edge[2]))
orient.db_close()
def print_leaderboard(deps):
vertices_ins = {}
for dep in deps:
if dep[1] not in vertices_ins:
vertices_ins[dep[1]] = 0
vertices_ins[dep[1]] += dep[2]
vertices_s = sorted(vertices_ins.items(),
key=lambda x: x[1])
for v in vertices_s:
print v
def main():
files_list = get_file_list()
deps = read_dependencies_from_files(files_list)
print_leaderboard(deps)
save_graph(deps)
if __name__ == '__main__':
main()
Usage
The script accepts list of files in stdin.
find /path/to/your/project -name "*.h" > my_project_files.list
find /path/to/your/project -name "*.cpp" > my_project_files.list
cat my_project_files.list | python cpp_dependencies.py
Some notes
- I have used multiprocessing for faster files parsing.
- For faster saving into database please go to web interface and create schema/index for cppfile.name
- It prints leaderboard of cummulative in vertices(some kind of vertex centricity)
- You will need to do
pip install pyorient
Playing with the orientdb
Go to web interface and choose graph.
Now we can make a traverse from a file to see who is including this file and how.
TRAVERSE in(), inE() FROM (SELECT * FROM cppfile WHERE name='util.h') WHILE $depth < 10000 LIMIT 10000
And you will get a nice graph dependency for "util.h".
But this can be very slow in case of many nodes.
To display file names instead of ids just click on any node, click on eye icon(show), go to configure and choose name.
Visualization
The orientdb web client is not good enough when it comes to visualization of big one graphs.
Here you will need something more powerful. I have searched across the internet and the most suitable project I found was Gephi.
http://gephi.github.io/
To connect gephi to orientdb we will need to install streaming plugin.
Please see instructions in detail here - https://code.google.com/p/orient/wiki/Gephi
For full includes whole graph just add next stream - http://localhost:2480/gephi/cppdepdb/sql/select%20from%20cppfile/500000
screenshot of gephi visualization
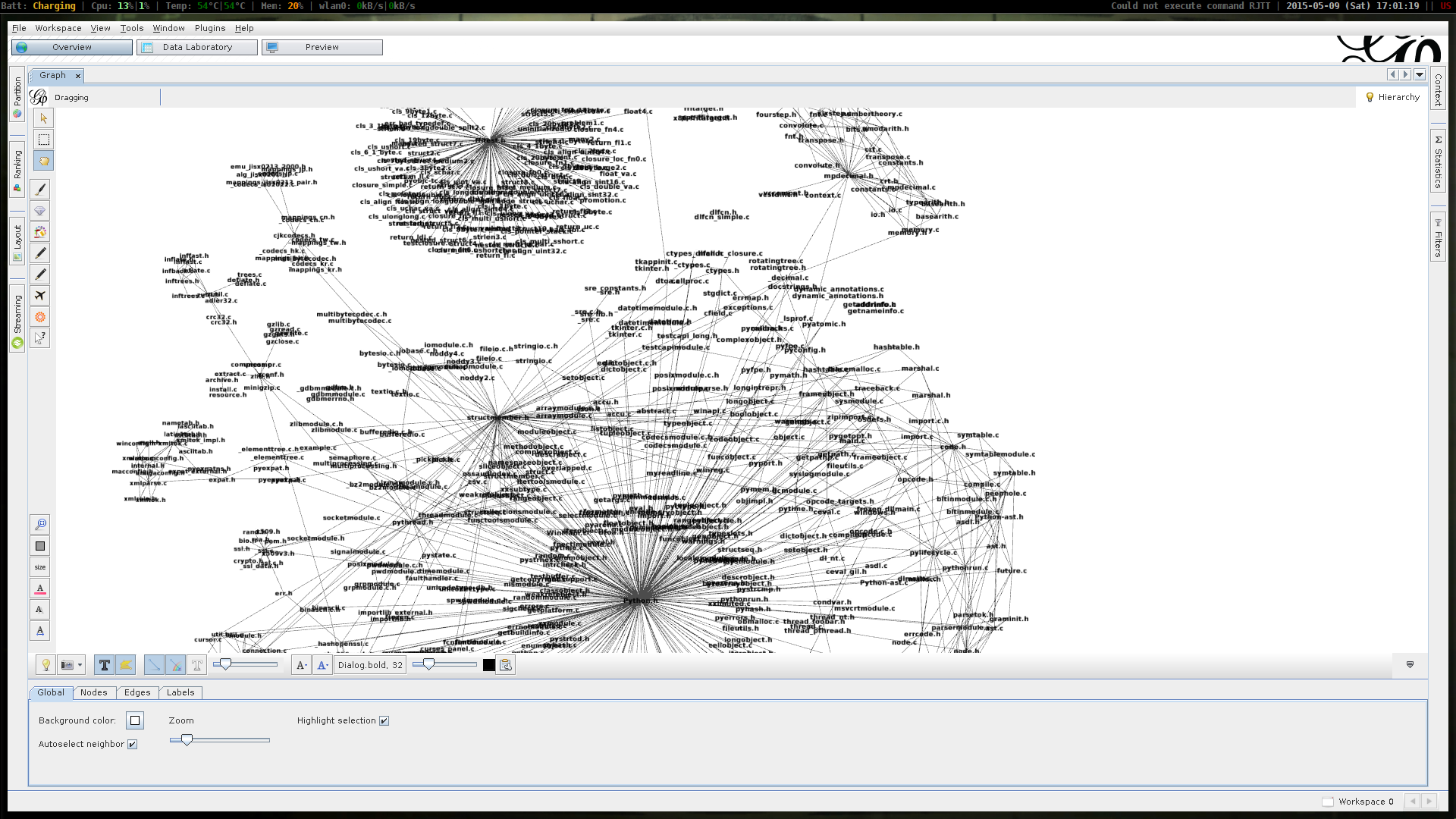{kind=link}
You can also visualize traverses which sometimes can be useful.